Hoje vou mostrar como navegar nos links de uma página com Python ( raspagem na web ). Isso pode ser muito útil para rastrear o conteúdo de um site automaticamente e não ter que ser feito manualmente. No programa que trago para cada link é obtido através da leitura do html, você pode modificar o programa para procurar um determinado conteúdo e mostrar apenas os links nos quais está interessado.
Você também pode fazer a raspagem da Web usando o arquivo robots.txt ou os mapas de site que os sites possuem.
Nota
O código mostrado funciona no Python 3.x, se você quiser executá-lo na versão 2.x, precisará fazer pequenas modificações.
Então deixo o código:
fila de importação import urllib.request import re de urllib.parse import urljoin def download (página): try: request = urllib.request.Request (página) html = urllib.request.urlopen (request) .read () print ("[ *] Faça o download de OK >> ", página), exceto: print ('[!] Erro ao fazer o download', página) return None retorna html def crawlLinks (página): searchLinks = re.compile ('] + href = ["'] ( . *?) ["']', re.IGNORECASE) fila = fila.Queue () fila.put (página) visitada = [página] impressão (" Procurando links em ", página) enquanto (fila.qsize ()> 0): html = download (fila.get ()) se html == Nenhum: continuar links = searchLinks.findall (str (html)) para o link nos links: link = urljoin (página, str (link)) if (link não está sendo visitado): cola.put (link) visit.append (link) se __name__ == "__main__": trackLinks ("http://www.solvetic.com") A primeira coisa que fazemos é importar as bibliotecas necessárias, para expressões regulares (re), usar a fila (fila), fazer solicitações e ler uma página (urllib.request) e para a construção de URLs absolutas de um URL base e outro URL (urljoin).Código dividido em 2 funções
baixar
Isso nos ajuda a baixar o html de uma página. Não precisa de muita explicação, basta solicitar a página desejada, ler o html; se tudo correr bem, será exibida uma mensagem OK Download; e se não mostrar que houve um erro (aqui poderíamos mostrar informações de erro), no final retorna a leitura de html ou Nenhuma.
trackLinks
É a função principal e passará por cada link. Vamos explicar um pouco:
- Criamos uma variável com uma expressão regular, o que nos ajuda a encontrar os links no html.
- Se iniciarmos uma variável de tipo de fila com a página inicial, isso nos ajudará a manter os links na "ordem" que descobrimos. Também iniciamos uma variável de tipo de lista chamada visitada que usaremos para salvar os links à medida que são visitados. Isso é feito para evitar um loop infinito, imagine que uma página x se refira à página y e, por sua vez, à página x, o tempo todo inseriremos esses links infinitos.
- O núcleo da função é o loop while, que será executado enquanto a fila tiver links, portanto, verificamos que o tamanho é maior que 0. Em cada passagem, pegamos um link da fila e o enviamos para a função de download, que o html nos retornará, imediatamente procuramos os links e verificamos se já o visitamos; caso contrário, o adicionamos à fila e à lista.
Nota
Pode parecer que a lista foi deixada, mas, na fila, removeremos e excluiremos os links, para que a verificação não esteja correta, talvez o link que visitamos há um tempo atrás e não esteja mais na fila, mas estará dentro a lista.
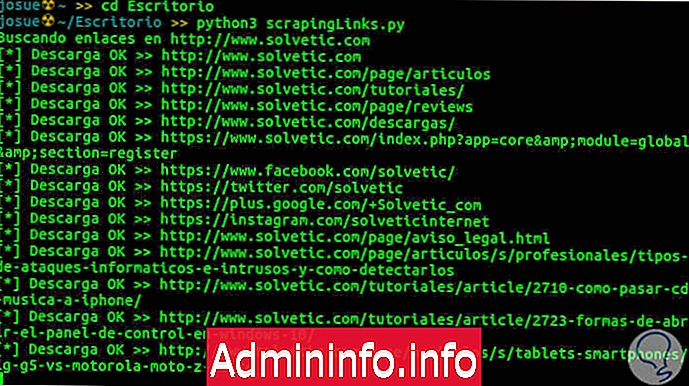
A última parte do código que já está fora das funções será responsável pela execução do código. Na imagem a seguir, você pode ver uma captura do código em execução, rastreando solvético.

Se você quiser se ajudar com uma biblioteca que existe para python chamada BeautifulSoup, parecerá muito fácil de manusear, eu recomendo.
Caso você queira o código, aqui está um zip:
RecorrerEnlaces.zip 646 bytes 281 Downloads

- 0 0
Artigo